
很明显最近一两个星期都忙,忙772的assignment1. 虽然assignment 1的目的只是让我们熟悉Rapidminer这个工具,但因为数据的问题,想要做好还是挺麻烦的。。
数据集是包含3000个样本的工作保险数据,包含以下的变量:
- 保险号ID,ID,不并不算在分析范围内
- 详情记号,一堆文本,也不算近分析范围内
- 保险的理由,起因,以及损伤的身体处,算是多项,算在分析范围内
- 第三方责任的tag跟包含汽车的tag,因为只有0和1,算在分析范围内
- 被确认骗保的tag,也是只有0和1,是主要的预测对象
这次的数据集最大的问题是样本的不平衡。。作为被predict的目标骗保tag,3000个样本里面只有93个是正的,这样的话一般情况的建模肯定性能会很糟糕的,因为大多数模型都是对各个情况“人人平等”的,某类样本少的话就很难学习到这种少数类样本了,有些甚至在学习的时候根本就忽略了这类样本,得出来的模型就与“预测小数派”这个目的背道而驰了。不过老师貌似也预料到我们做出来的性能不会好。。就说目的是让我们熟悉Rapidminer的操作而已。。嗯_(:з」∠)_
虽然老师说是不追求性能,把过程做出来就好名单还是介绍了点应对不平衡数据的办法的,大概有这么几种:
- 改善采样
- 换模型,或者模型的ensemble
- 用loop operators尝试模型的参数,调整Threshold
- 以及改用其他的模型性能评判方法
改善采样
需要注意的是采样改善后的数据只能用于模型的训练,不能拿来验证跟测试。。毕竟如果连验证跟测试都是用重采样的“注水”数据的话,就不适用于一般的场景了。。(现在看起来性能很好,但拿出去了很糟糕。。)
主要还是分两种思路:
- 把正负样本分开然后单独处理
这个方法虽然听起来比较简单,但实际上搓起operator来是要比第二种方法要繁琐一点的。这种在课堂上叫balance sampling,也有这么两种思路:
- 单单采用一个sampling operator,把参数调成balance sampling,像这样:
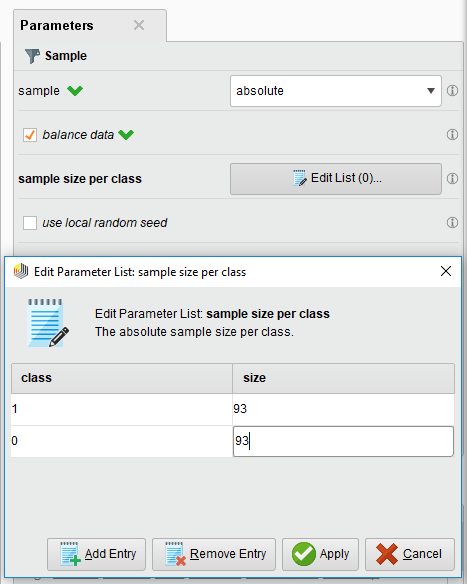
这样只要从这个sample出来的数据就是93份正跟93份负的样本了。虽然这样是平衡了,但有一个很大的问题是这样用来训练的样本就只有186个了,势必会丢掉很多很多的数据跟特征,所以还有别的方法。
2.把正负样本分开,少数的正样本上采样(up-sampling),多数的负样本下采样(down-sampling)
这样操作就比较繁琐了,(跟其他的比起来)过程是这样的:
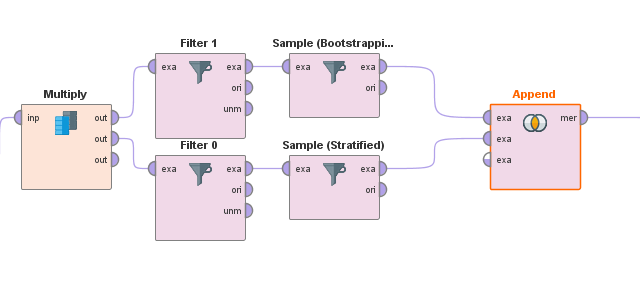
首先用multiply把数据复制成两份,然后用两个过滤器(Filter), 把数据分成有正样本跟负样本,载然后把少数的正样本上采样(例如像这里用boostrapping多了5倍),把多数的样本负采样到跟正样本一样的数量,再用append糊在一起。这应该算是更进一步的采样方式了,不会让正样本太少模型不好学,而且用起来感觉效果也跟下面的SOMTE比较贴近了。。然而还是不太够了。
- 采用一些综合的采样算法
嗯。。这里就是首推SMOTE了。介绍看这:
emmm。。SMOTE是怎么做到改善样本就去看吧。在Rapidminer里面我们只是需要安装Operation Toolbox插件,然后把这个operator拖进去而已。。记住是只处理用来训练模型的数据,验证跟测试不要用这种处理过的数据就好。位置的话一般跟在classifier前面就是。。无论用不用cross-validation。
当然,除了无论在哪里都首推的SMOTE,其实还有不少其他的采样方法的。这时候就推荐一个叫Information Selection的插件,里面也有不少的采样插件可以用,里面有些也不比SMOTE差。。(这次用的ENN还行比SMOTE还好那么一丁点。。嗯)
当然,如果要“完全体的采样改善”,Rapidminer就算有插件加持,其实也没有传统的R之类的工具要多功能的。。像有些像改进的Borderline-SMOTE,Easy Ensemble之类的Rapidminer根本找不到。。感觉还是有点必要挖坑的。
换模型/模型Ensemble
嗯。。对于这次这种总样本数少,正样本数更少的case,单在采样方面下力是不够的。在模型的选择跟组合上也是颇花功夫的。当然,上课时候拿来入门的k-NN已经不太适应了,换先进一点的模型+ensemble就成了大势所趋(在这assignment= =)
模型的ensemble主要有以下这么几种形式:
- Vote
- Bagging
- Stacking
- Boosting – 又分adaBoost 跟Gradient Boost
- Random Forest (感觉表现不太好,并不会用。。)
里面的vote其实算是stacking的一种,“投票”看里面的模型哪个好就选哪个而已。。直观点的区别是这样的:
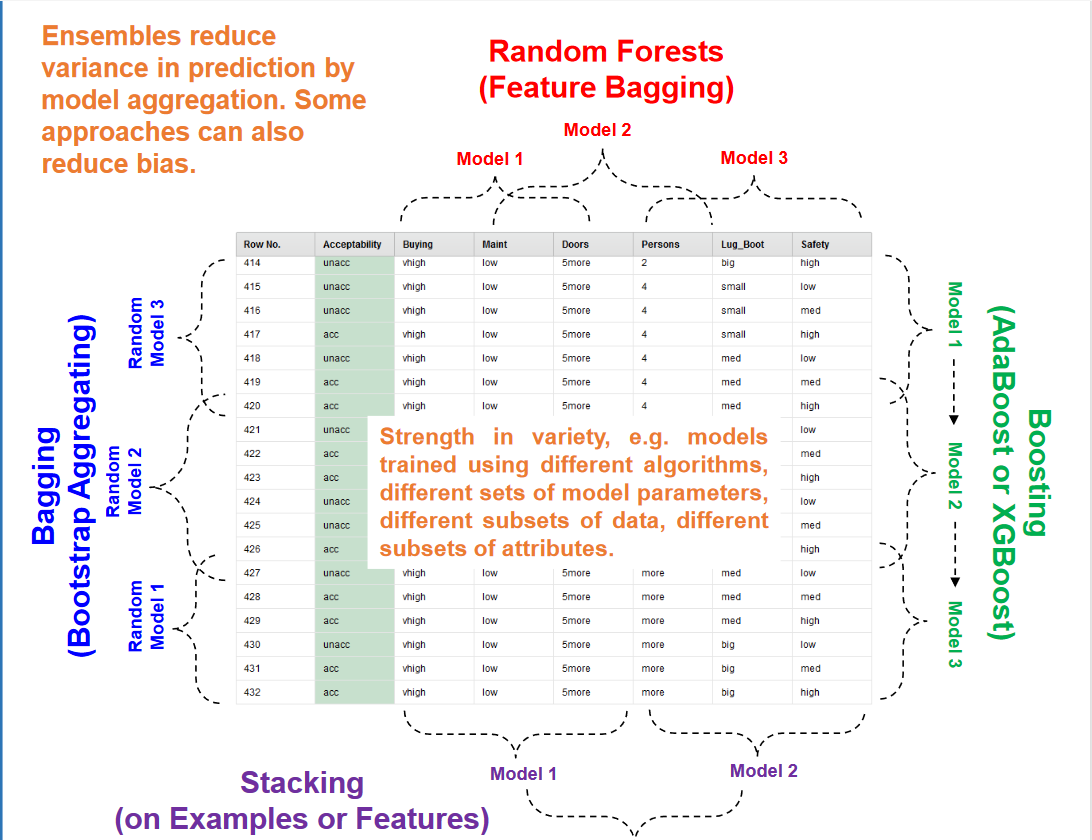
Bagging: 用不同的模型去试随机选取的样本并且测试,得出来的结果一般都是各个模型的输出的平均输出。。
Random Forest:一通乱炖.jpg,建一堆不同的模型,随机应用到不同的样本中(这次也没用。。。)
Boosting:一步一步地建模。。下一个模型会基于上一个模型做改善。。无论是adaBoost还是Gradient Boost在这次作业中也是算比较好的了。。尤其是Gradient Boost,甚至还是主力。。
Stacking:做一堆模型,然后再用一个模型去评判哪个好。。性能还行,第二选择。。
然后这次assignment的主力(其中之一)就是gradient boost trees了,自带ensemble还性能不错。。然而虽然已经算最好的了,Kappa还是只有0.3.。
Loop operators调整参数+threshold
这个嘛。。没什么好说的,主要都是靠把模型放进loop parameter里面,设定尝试哪些参数,然后就拿最好的参数进模型,当然试threshold也是这个意思。
然而这时整个assignment中最长最痛苦的过程。尤其是去loop cross-validation的参数,有多少fold就loop多少次。。最长记录跑了4个半钟。
能loop的参数其实就那么几种:
- k-NN:k
- 各种decision trees(包括GBT):树的数量,深度
- cross-validation:number of folds
- Threshold:threshold阈值
然后操作大概是这样的:
loop 模型跟cross-validation:
loop threshold:
如何调参数:(GBT为例)
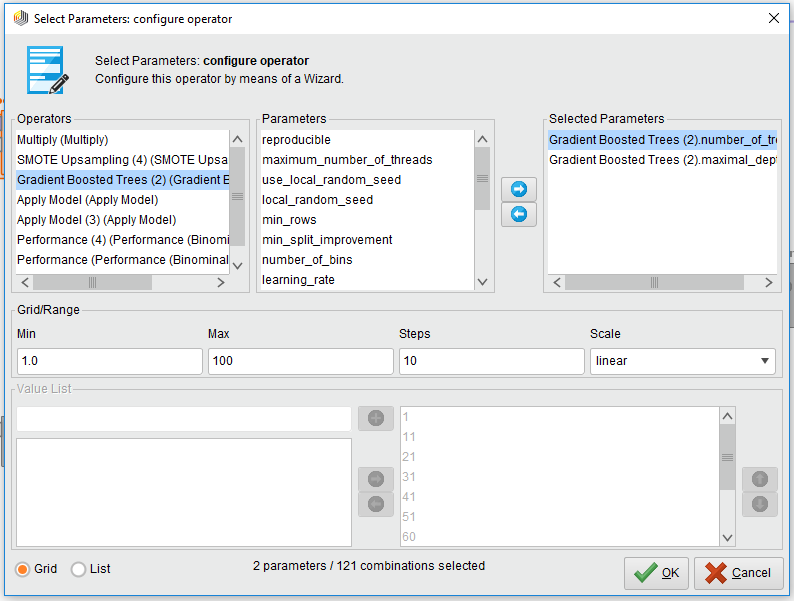
得出来的结果感觉还是可以的。。
改用其他模型评判标准
很明显在这种不平衡的情况下传统的accuracy已经很难正确预估小数派的变量了。这时候能用的一般就是Kappa,AUC/ROC,统计true positive等四个情况等等。。
对于Kappa的话,确实是挺直观的方法。。越高越好,一般0.5以上才叫能看。。但在这个case里面能有0.3已经不错了。。唉
对于AUC的话,是长这样的:
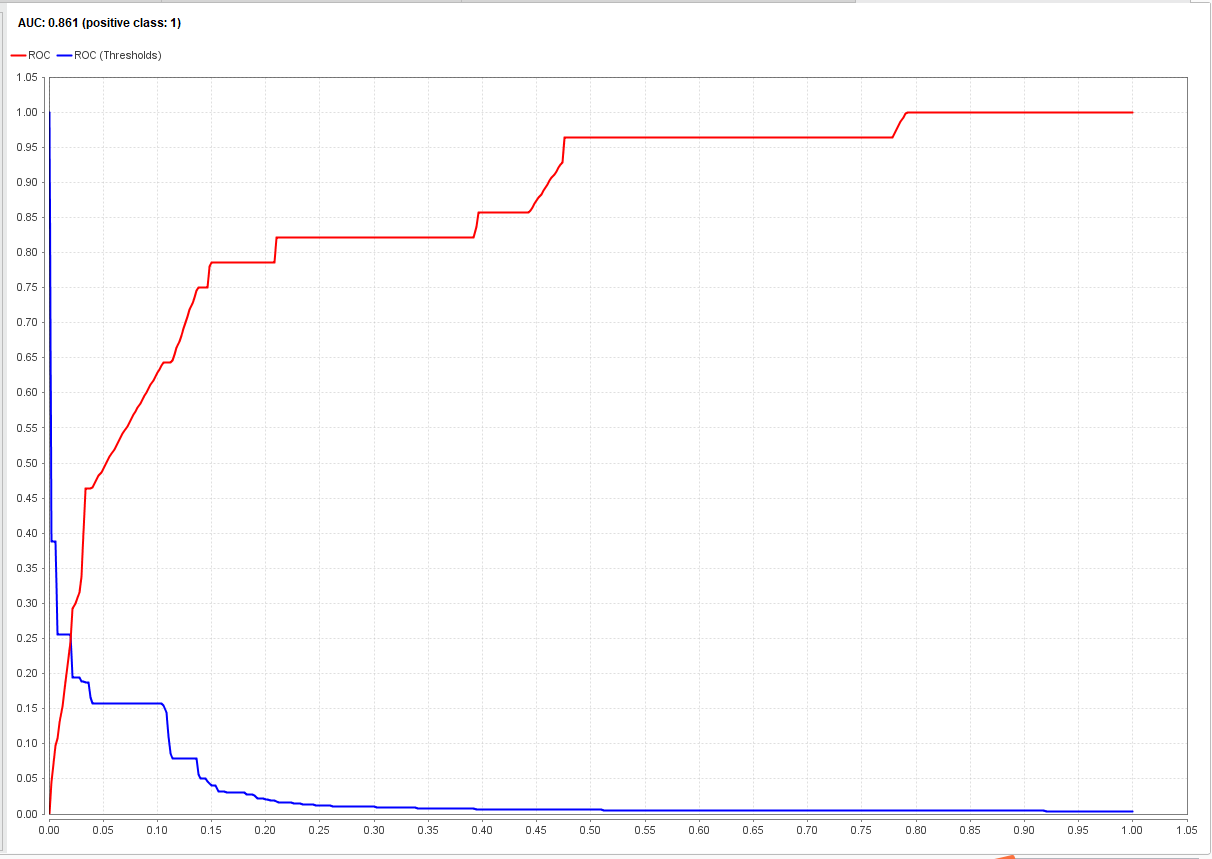
红线(ROC曲线)通俗来说就是显示模型“预估到正确的正样本的可能性”,一般约往左靠约陡,性能就越好。这种方法可以在样本变得不平衡的情况下保持一样的曲线,所以拿来评判这个case里面的模型的性能还是不错的。详细还是看维基吧= =
还有更多的解决方法吗。。。。
当然有。不过Rapidminer的功能还是不够多,其实还是有更多更好的方法的。。例如给模型加cost,用cost-sensitive的算法,或者转换成异常检测的问题。。先贴点链接记一下吧= =
先这样吧。。反正交了= =
以后再有再写。。。