
嗯。。昨天的Predictive Analytics开始讲熟悉操作以外的内容了,主要关于classification。课堂主要分为:
- 分类-classification的一些定义什么的
- k-NN 最简单的模型(Lzay)
- Cross validation-交叉验证
- Model evaluation and optimisation
- 以及并没有时间讲的decision tree-决策树
- 于是用RapidMiner演示一下各种操作。
Classification
并没有什么难点,知道class-类跟classification-分类啥的就差不多了
k-NN (k Nearest Neighbor)
基本的一些东西
- 一个相似度模型(similarity model)
- 大概方法就是有这么一个东西,它问它附近k个东西是什么属性,什么属性占优那他自己就是这个属性
- 例如k=5,a附近的5个个体有三个是x,有两个是y,那a就会觉得自己是x
- 这模型很懒-Lazy model
- 因为不少时候情况复杂,通常会用一小部分的样本数据去训练k-NN模型,那小部分数据就叫做prototypes
- k-NN也能用来识别异常变量-如果它离它的邻居都很远的话。
距离的计算
课堂上介绍了两个方法:
- Euclidean distance – 直线距离,在图标上需要计算
- Manhattan distance – 图标上横+纵坐标加起来的距离,对付outliers会好一点。

建模的过程
一般就是拿到预处理的数据然后:
- training:用一些数据去建立分类模型
- validation:用训练数据以外的数据去测试模型的准确性
- deployment:
Evaluation
关于模型的评估,课堂最主要介绍的方式是confusion matrix – 混淆矩阵,附以一些其他方面的说明。
Confusion matrix
一般Rapidminer里面的混淆矩阵是长这样的:
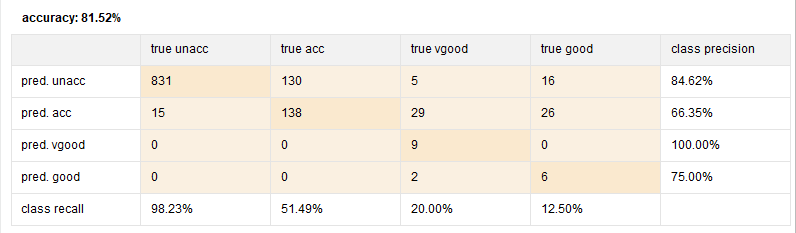
emmm…作为混淆矩阵,最主要的功能是用validation的数据去验证模型的结果,并且给出模型的精度(性能什么的。。)
首先混淆矩阵中间的格子有这么4种情况:
TP:true positive,真实是unacc,预测也是unacc
FN:false negative,真实是unacc,预测却是acc
FP:false positive,真实是acc,预测却是unacc
TN:true negative,真实是acc,预测也是acc
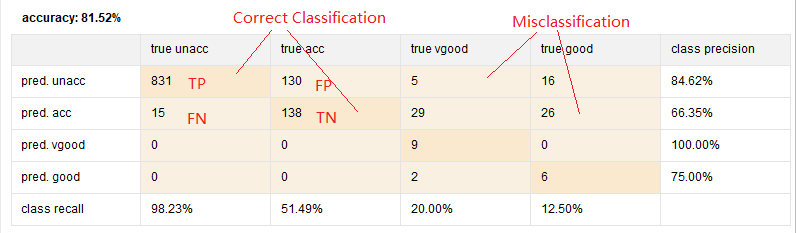
预测总样本数是1207,目标是预测acceptable的性能。。
图表的右侧是预测各个情况的准确率。。例如第一行就是预测unacc的准确率,第二行预测acc的准确率(accuracy performance)。。以此类推。算起来也挺简单,只要把TP或者TN除以同行加起来的总数就成了,例如:
pred.unacc:831/(831+130+5+16)=84.62%
下面的class recall又叫差全(召回)率,算起来也挺简单,纵向除以总数就成了,例如:
true unacc: 831/(831+15)=96.23%
至于整个模型的准确率的话,把所有的TP跟TN加起来,然后除以总数就成:
(831+138+8+60)/1207=81.52%
当然,也有右边的那两个misclassification的格子显示了模型有哪些是预测错误的,一般misc=1-accuracy。
然后performance operator还有一种叫Kappa系数的方法,用于检验一致性,衡量分类精度。一般有很高的accuracy但是Kappa系数很低的话模型也是不行的= =
Kappa系数的计算:

![]()
![]()
![]()
Kappa系数看起来还是可以的。。0.527属于有中等的一致性,一般低于0.2就是一致性比较低了。。
Bias and variance trade-off
Bias:模型结果的偏向程度。如果模型的预测结果大多数都是集中一块但有偏向的话bias就比较高了。。
Variance:模型预测的结果的离散程度-离散程度太高的话也预测不到什么东西。。
一般bias跟variance是互相对立的-然而他们都是负面影响,嗯。
Cross validation
三种方法:holdout(留出法),k-flod,LOOCV
Holdout:
将数据分成三部分:训练集,验证集和测试集(training,validation,testing),训练用于出模型,验证用于调参数,测试用于测试泛用性。。
方法简单,分数据即可,但显然性能不太好。。也不太会用
k-flod:
k折交叉验证,步骤:
- 不重复抽样把原始数据分成k份
- 每选一次挑其中一份做测试集,剩余的k-1份当训练集
- 重复k次-训练-测试,重复k次
- 计算k组测试结果平均值为精度估计
- 一般k是10次,看有多少数据而定。。。

重复而且随机的抽样让k-flod CV不会像holdout那样那么“对划分敏感”,一般都是用k-flod的了。
LOOCV:
leave one out CV
其实是k-flod的一种,只不过用于样本较少(数据缺乏)的时候。k=样本总数。。嗯,拿总体数据的一份去testing,然后其他的都去training,就是LOOCV了。
Boostrapping CV:
自助采样法,比较特殊的一种,把数据集分成m份样本,每分一次就抽一个样本出来再放回去。抽完以后就有一个新的数据集做training了,其他的就可以用来做validation了。平均来说只有63.8%左右的数据会被选取training,并且有一小部分的数据没有用上,所以其实并不常有。
第三周的课大概就讲了那么多。。其实并没有讲完,还有decision tree什么的。。
RPM文件:Rapidminer Res-MIS772-week3