
MIS772 – Predictive Analytics,被誉为我们MIS里面最难的一门,到第二个星期就有due了。。不过听说跟上个学期有所不同,据说没有了R啊,Python什么的,只有一个叫RapidMiner的傻瓜式(相比之下)的工具,就省事了不少。。
Assignment 1 LP1 感觉是致力于熟悉RapidMiner的基本操作,导入表格啊,看看初步的图标啊,什么的,还只是descriptive analytics的层面,开始建模是LP2的工作。。
首先Rapidminer的界面是这样的:
人懒就不太介绍界面什么的了。。反正RapidMiner是用流程(process)去分析数据的,操作就是在左下角的operators拉操作进process框来做读取数据啊,筛选啊,建模之类的操作,然后末尾拉去process框的右侧result处,点一下顶上的播放符号就能条到result那边出结果了,嗯。。
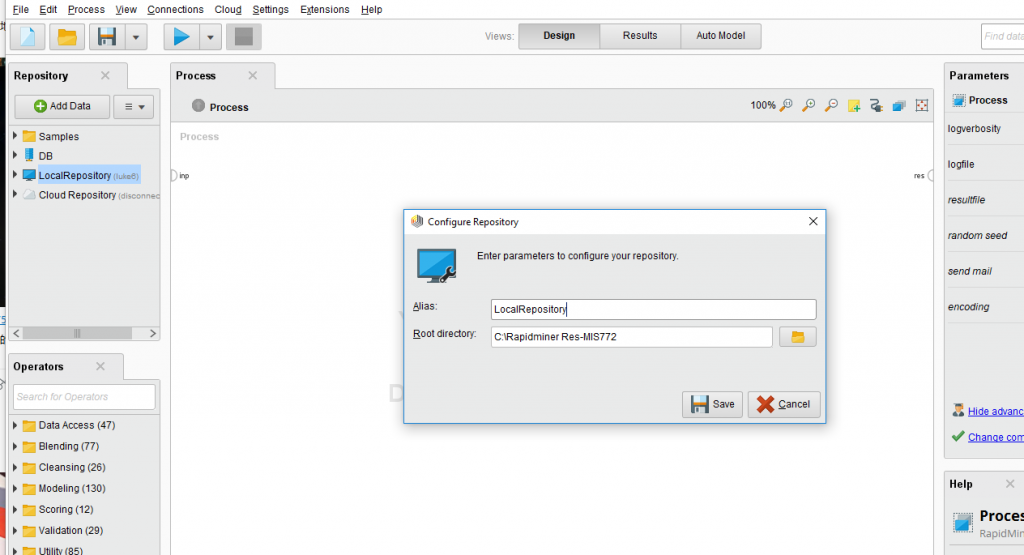
首先得改一下repository的地址,不然的话交作业要交process文件的话找目录位置会挺麻烦的。在repository功能里面右键local repository,选config那啥,就能改local repository的位置了。
然后根据目的,我们需要读取数据,筛选数据,设置自变量,(或者说标记变量)复制一份出来做correlation matrix并且原来那份输出做图标,就有了下面的process:
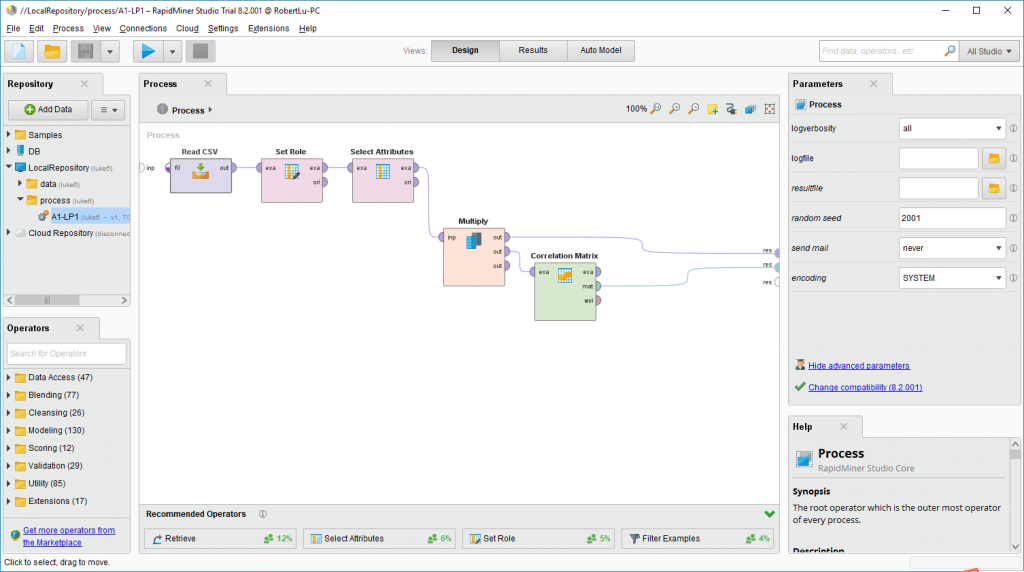
Read CSV:读取数据,这里是csv文件就read csv,是其他的就其他。。
Set Roles:筛选变量,把不需要的变量给筛选掉,像备注什么的。。
Select Attribute:设置变量(标记变量),被标记的变量会在result里面被标记为绿色并且前置,用来辨别分析对象。。
Multiply:简单的把数据复制一遍
Correlation Matrix:相关矩阵,用以显示数字变量之间的相关性。一般>0.5就有一定关联了。
Read CSV
首先是Read CSV operator,它是有一个向导去导入数据的:
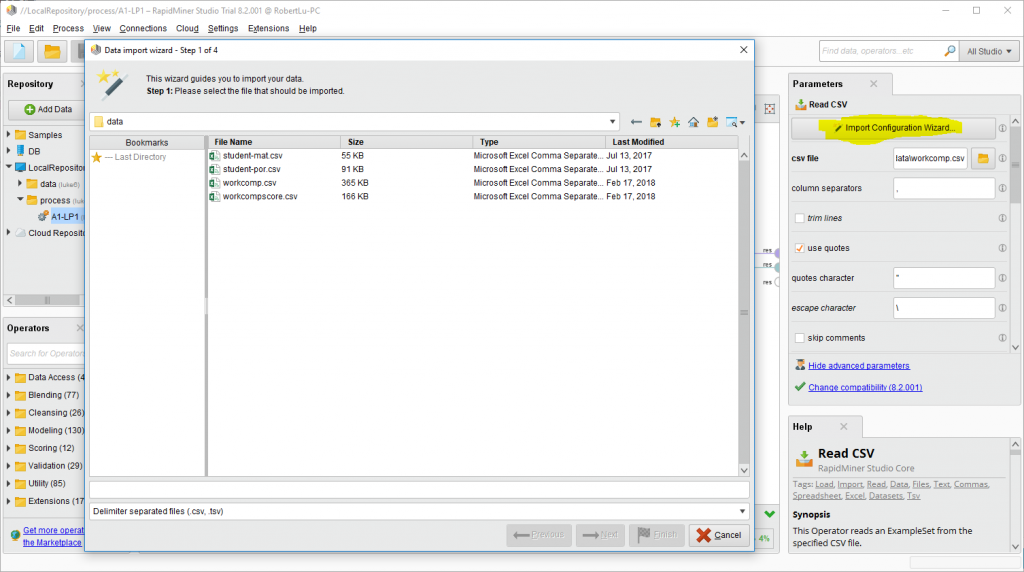
首先是这个,简单地选个文件就好了。。这作业是workcomp.csv,然后下一步。
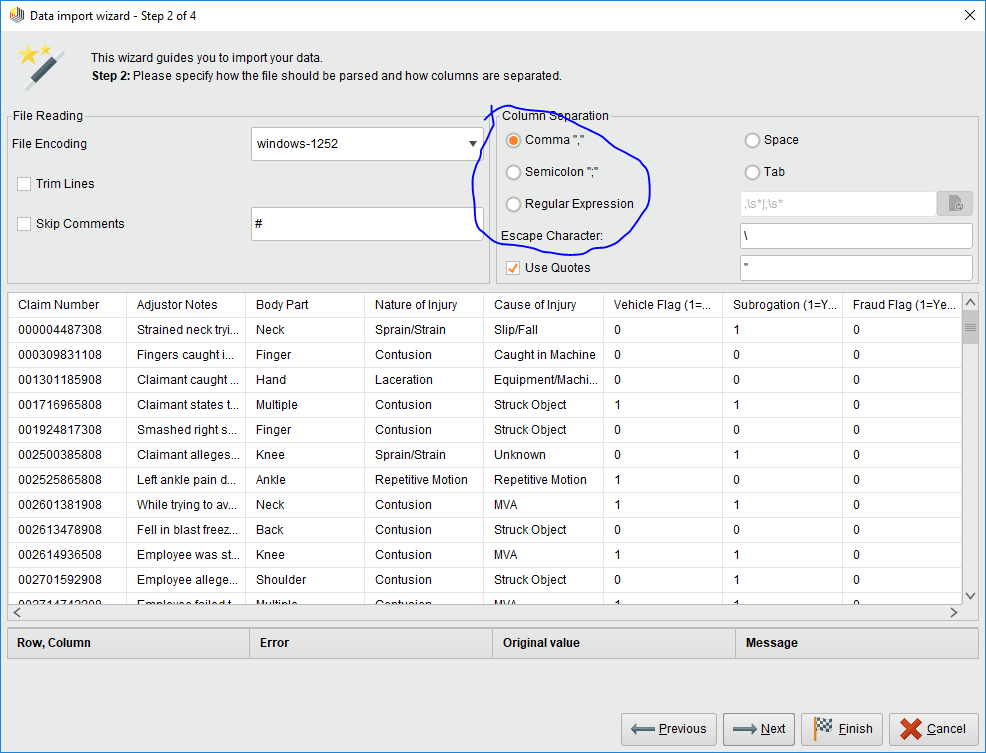
这里就要注意以下蓝圈圈住的部分了,这是选文件内的分割格式的。。选着看起来跟图那样像个表就好了。
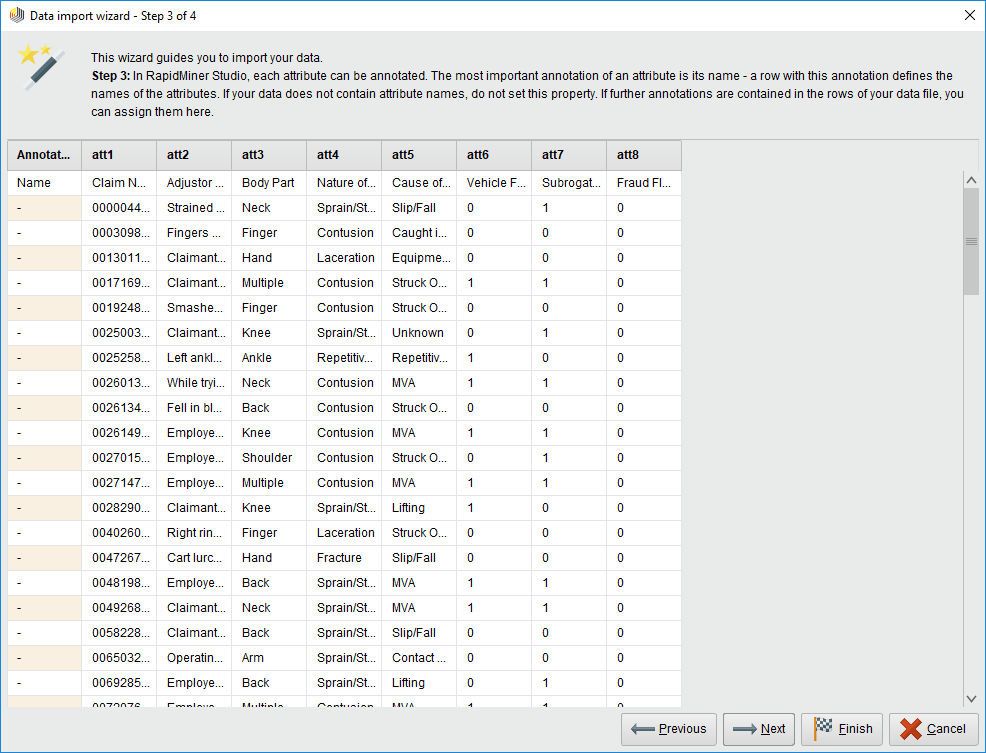
再下一步就是整理行首了。。如果行首有什么备注的话就能在最右边的annotation标注掉,就不会影响下面的数据了。
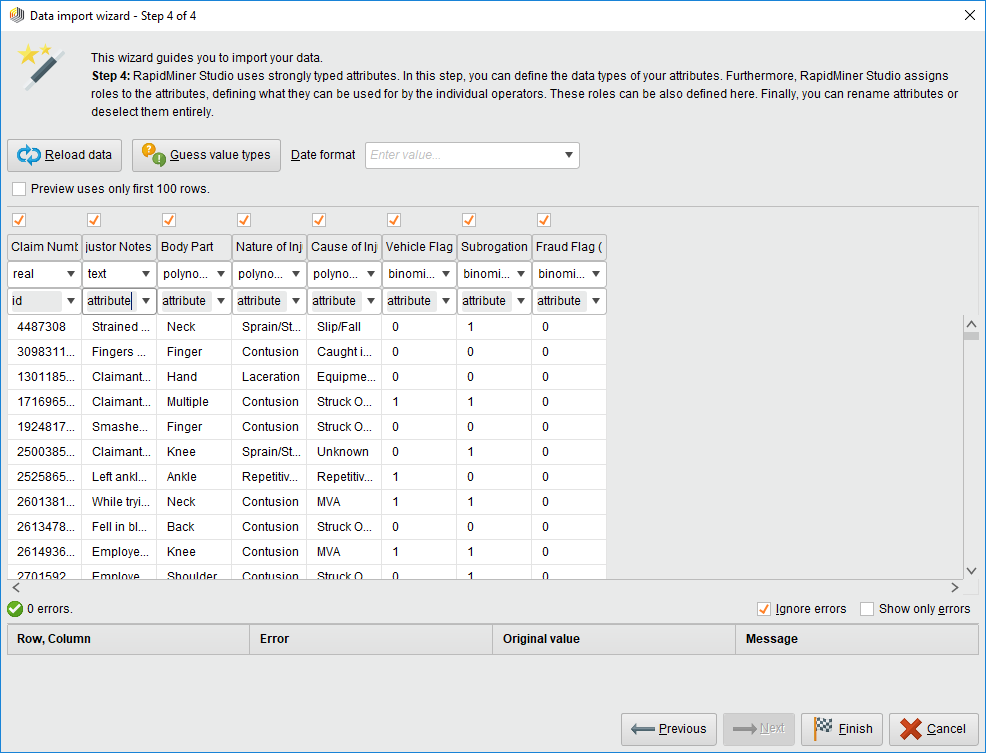
这一步算是导入数据的最后一步了,选择数据的类型,也是导入向导里唯一需要思考的地方。。首先这里不会用到所有的数据类型,大概只会用到这么几种:
real:一般的数字,并没有什么意味
ID:用于第一列的claim ID,说明这是一列ID,并不会在数据分析过程内出现
Attribute:Rapidminer里面的变量,一般都是数据分析对象。
Polynominal:多项式,这里面的body part,nature跟cause都是一堆分类,所以算是多项式。
Binomial:二项式,一般只有是或否,后三个flag就是这种变量。
完成后点finish就得了。
Set Role
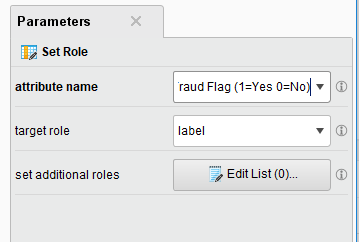
并没有多少东西。。在这assignment里面只是标记一下需要标记的变量而已(这里是fraud flag),以便于在输出的时候便于辨别与分析。attribute name选变量,traget role 选label就成了
Select Attributes
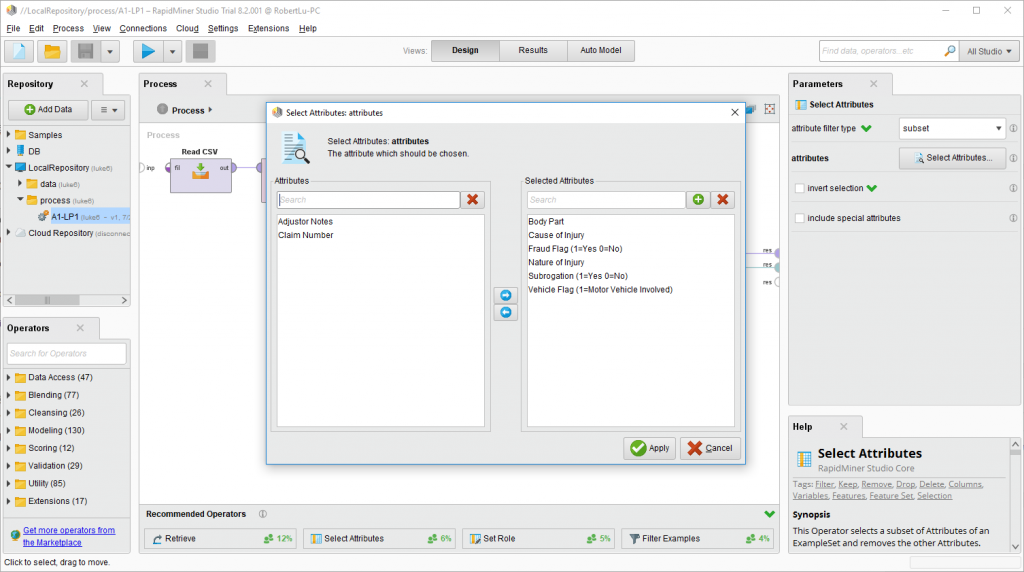
嗯。。这一步(operator)就是把不需要的变量筛掉的。右边的属性选subnet就能筛选多个了,然后点下面的select attributes,把需要的变量选到右边去然后确认就完成了。这里不需要的变量是adjustor note – 一堆文字的解释说明还有claim number – 单号。
Multiply
简单地把数据复制一遍,有多少个结果拉多少条就成了。
Correlation Matrix
所谓的相关矩阵,就是拿来看看各个数字变量之间的相关度的,一般>0.5就能说有一定的关联性的,正的就是正比例-负的就是反比例。
RapidMiner的correlation matrix能从参数里选择需要的变量,而不需要另外再select attribute,于是就是长这样的: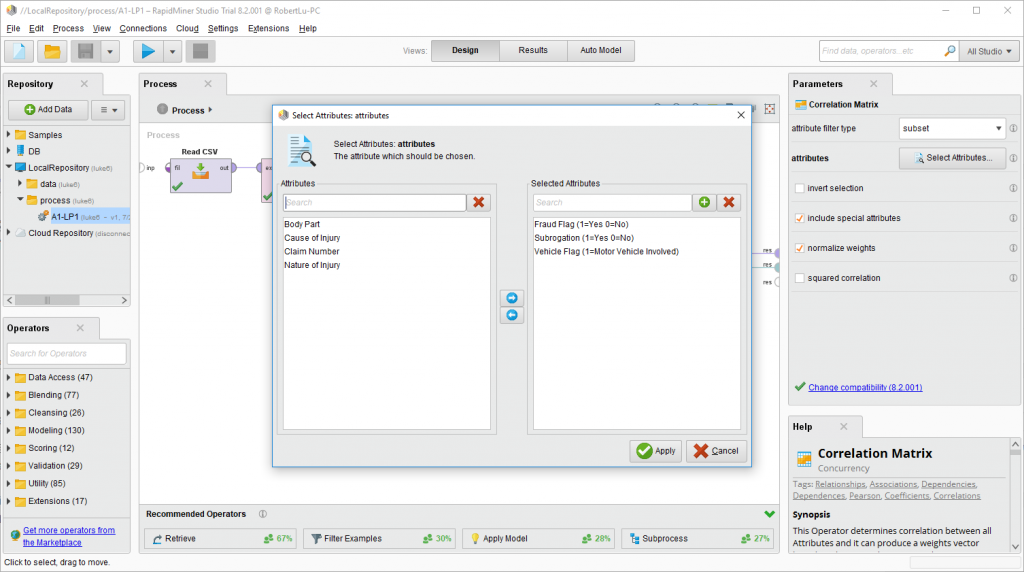
也跟select attribute一样subnet,然后选三个tag到右边,再然后勾上include special attributes(因为这几个都是binomial)跟normalize weight,然后都连起来就是第三张图的样子了,点一下上面的三角运行一下。。。
一开始跳到result history,只是显示运行历史,并没有什么东西,然后点开correlation matrix看看。。
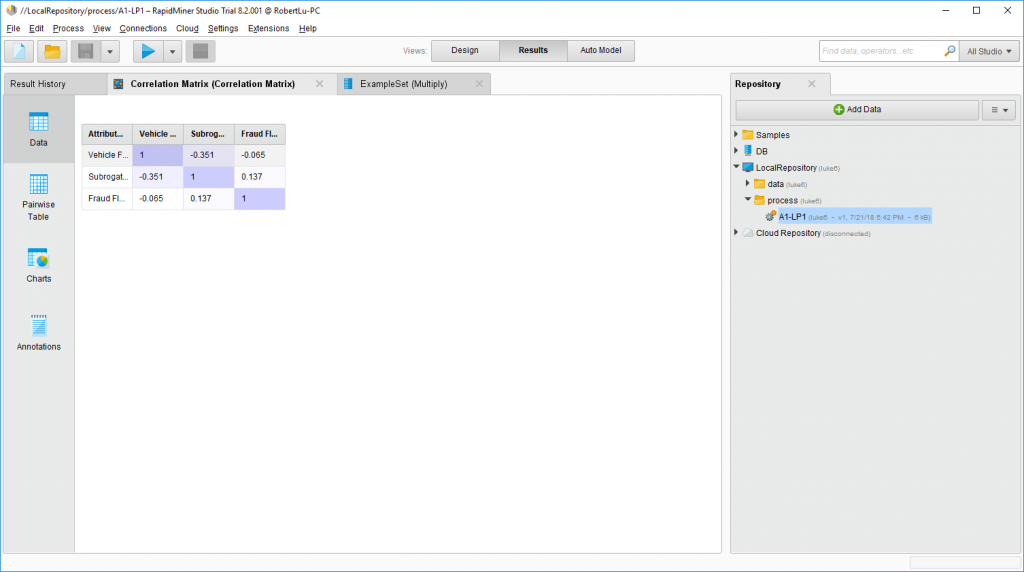
挺简洁的相关矩阵,显示了这三个变量之间的关联性并不大,有不少甚至是相反的关系。。嗯。
然后点去sample set,A1LP1的重点也是在sample set里面,首先可以看到是都列出来的数据:
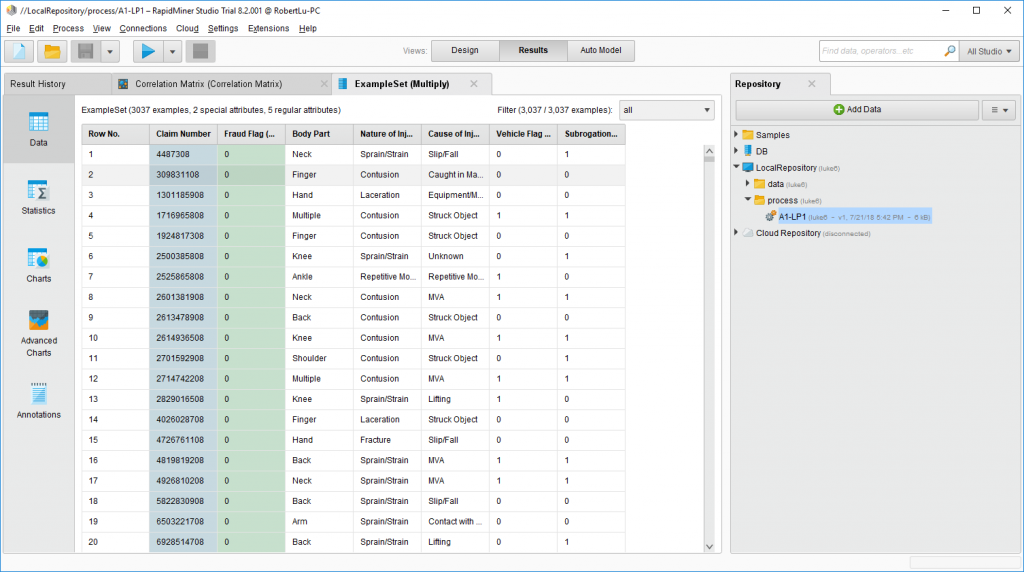
可以看见被定义为ID的claim number被标蓝了,也不太会搞进分析过程里面了,然后被label的fraud flag被提前了,就很容易看出是自变量,拿去分析其他数据的。然后再点去statistics。
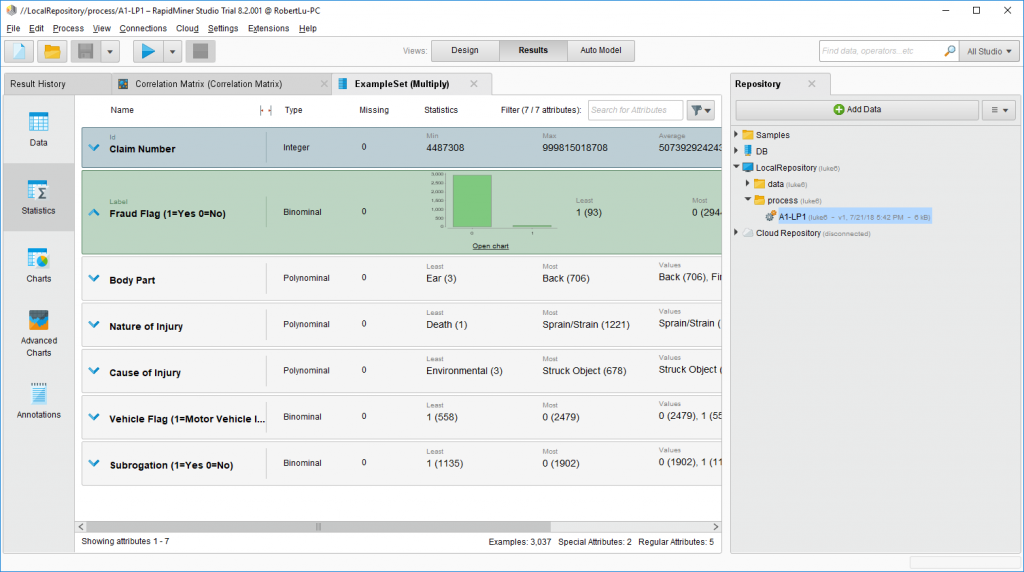
就是一个各个变量的总览。。挺好用的,然后再看看charts。
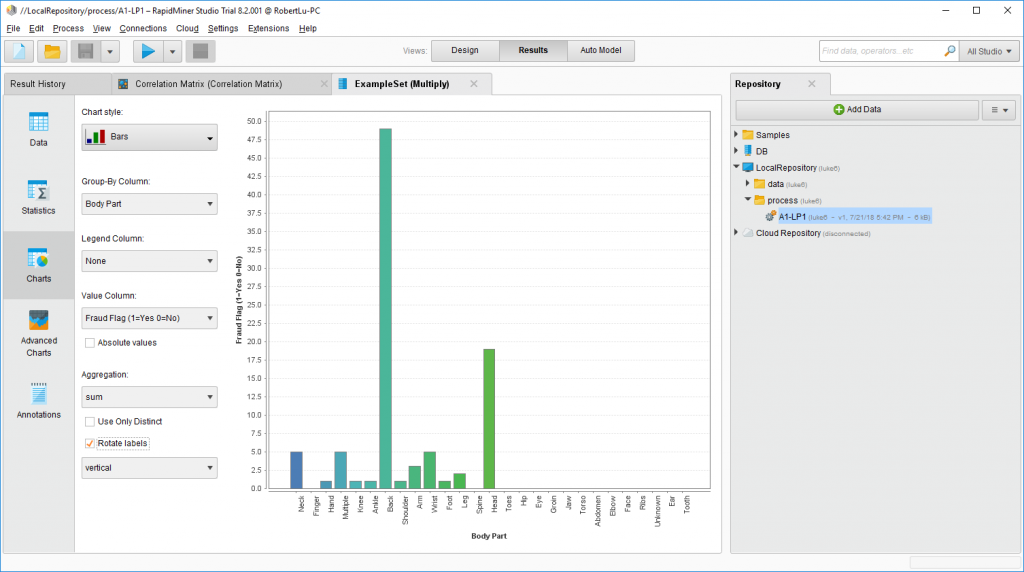
以显示按body part来分有fraud flag的保险为例,很明显背部出问题的保险的fraud flag是最高的,然后其他的图表什么的就另外再说了。。
总之A1-LP1的确只是想让我们摸摸RapidMiner而已,也不算太大问题。。就这样吧= =